

以往的视频处理和生成技术面临众多限制,但凭借自主开发的LSD模型,AI视频生成技术目前正逐渐崭露头角,同时取得了多项创新性的突破。

滤镜局限与AI生成潜力

传统滤镜的效能相对有限,其主要作用在于进行基础的色彩调整和样式设定,这就像是对视频进行一次基本的“化妆”处理,却未能对视频内容进行深入的分析和理解。相较于其他产品,谷歌的Veo3等AI生成视频采用的扩散模型展现出明显不同,这种模型能够精确捕捉所需生成视频的具体内容;它不仅限于滤镜的简单应用,还能同步创作出充满创意的AI视频;这一创新为视频创作领域拓展了新的发展方向。
LSD模型特点

该技术基于自主开发的Live(LSD)模型,实现了视频逐帧的生成,并保证了时间上的连贯性。相较于以往的方法,LSD模型展现出显著差异,它支持视频合成的全面交互性,使得在视频生成过程中可以持续进行提示、变换以及编辑等操作,从而突破了传统视频模型的功能限制。

传统模型问题
以往的视频模型存在诸多缺陷,它们要么生成固定长度且相对较短的影片,要么在采用自回归方法生成时,视频质量不尽如人意,输出结果通常较短。尽管定长模型在产出高质量片段方面表现出色,但其非因果性设计以及全片段推理过程往往导致处理延迟,从而限制了实时交互和系统的扩展能力。尽管分块推理在提升系统扩展性方面有所贡献,但它同时也降低了响应速度,并且可能累积误差。

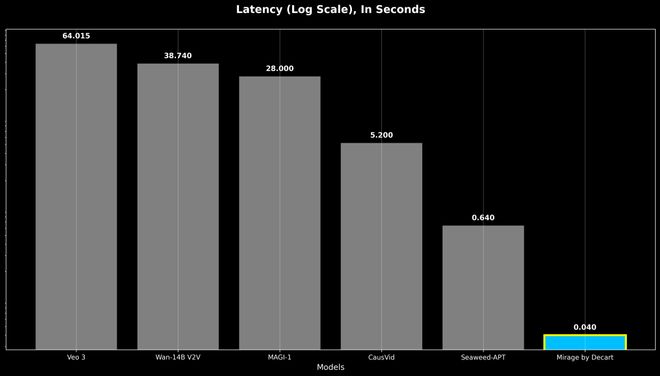
实时生成突破
这些技术之间相互协作,大幅提高了模型的反应效率,与过去模型相比,速度提高了16倍。这一提升使得模型能够达到每秒24帧的实时视频输出。实时扩散模型还在应用领域上进行了扩展,它被用于开放域的可提示视频生成,实现了零延迟、实时处理速度和前所未有的极高稳定性,这一成就超越了以往任何组合的成果。
交互性优势

过往的视频生成系统在处理视频片段时常常出现时间上的滞后,这一特点限制了它们在交互式应用场景中的适用性。但LSD技术凭借其独特的因果反馈循环机制,确保了视频生成过程中的时间连续性。该技术能够不断调整自身,以适应视频内容与动作的变化,并能即时响应用户指令,生成连续的视频序列。更重要的是,LSD技术能够对输入内容做出即时反应,实现了无延迟的视频生成。
应用前景与意义
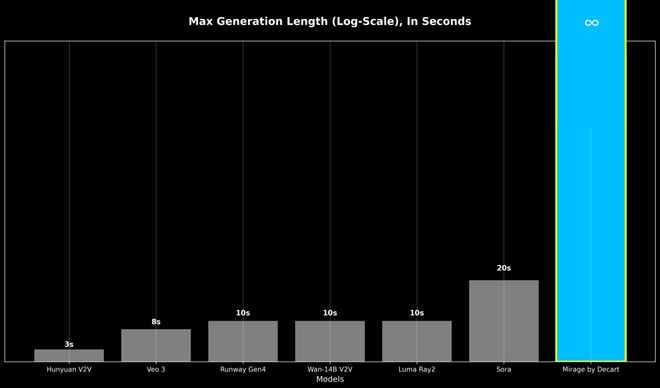
LSD的诞生带来了重大影响,特别是在直播领域。即便设备条件受限,它也能将直播画面转化为全新的视觉体验,实现所谓的“完美直播”。其逐帧生成技术使得视频制作更加灵活,交互性显著提升,为视频创作和直播等多个领域带来了革命性的变革。




发表评论